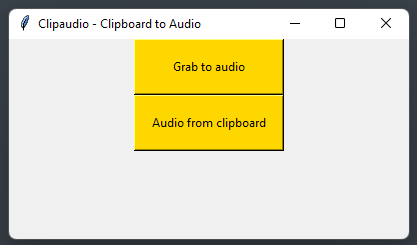
Pratically you select a text and copy it, then you launch the script (you can launch it also before copying the text) and then you press the button that says get clipboard to audio.
This Python script is designed to grab text from an image and then transform it into audio. The code does this by utilizing a combination of libraries and modules such as win32clipboard, pyscreenshot, pytesseract, pynput, tkinter, gtts, time, os, and PIL.
The script starts by importing the necessary modules and libraries at the beginning of the file. The pyscreenshot library is used to capture a screenshot of the user’s desktop, and the pytesseract library is used to perform optical character recognition (OCR) on the captured image.
The grab() function is then defined, which takes in four parameters: x, y, w, and h, representing the coordinates of the top-left and bottom-right corners of the screen region to capture. This function uses ImageGrab.grab() to capture the screenshot and saves it to a file using the save() function. It then calls ocr() to perform OCR on the saved image.
The ocr() function takes in two parameters: image, which is the path to the image file, and mp3, which is a flag indicating whether to convert the OCR output to an MP3 audio file. This function uses pytesseract.image_to_string() to perform OCR on the image and print the resulting text to the console. If the mp3 flag is set to 1, it calls the create_mp3() function to convert the text to an MP3 audio file.
The create_mp3() function takes in two parameters: text, which is the text to convert to speech, and lang, which is the language to use (default is English). This function uses the gtts library to convert the text to speech and save it as an MP3 file. It then plays the MP3 file using the os.system() function.
The clip() function uses the win32clipboard library to retrieve the text contents of the clipboard and calls create_mp3() to convert it to speech.
The on_click() function is called when the user clicks the mouse, and it captures the coordinates of the mouse click. When two mouse clicks are detected, the grab() function is called to capture the screen region between the two clicks.
The start() function is called when the user clicks the “Grab to audio” button in the user interface. It creates a tkinter window with two buttons, one for capturing text from the screen and the other for capturing text from the clipboard. When the “Grab to audio” button is clicked, it calls on_click() to capture the screen region containing the text.
Finally, the lab_print() function is defined to perform OCR on a set of image files, but it is not used in the current implementation of the script.
In summary, this Python script uses various libraries and modules to capture text from an image, perform OCR on the captured text, and convert it into an audio file. It provides a simple user interface to allow users to capture text from either the screen or the clipboard.
# grabscreen.py
import win32clipboard
import pyscreenshot as ImageGrab
import os
from pynput.mouse import Listener
import sys
import tkinter as tk
from gtts import gTTS
import time
from glob import glob
from PIL import Image, ImageTk
'''
Grab a text from an image
grabbed clicking on the left top corner
and right down corner of the part of the screen
with the text.
It returns it in the console
Then... it transform it into audio.
'''
import pytesseract
def grab(x, y, w, h):
im = ImageGrab.grab(bbox=(x, y, w, h))
save(im)
ocr("im.png", mp3=1)
def save(im):
im.save('im.png')
os.startfile('im.png')
trycount = 0
def ocr(image, mp3=0):
global trycount
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract'
text = pytesseract.image_to_string(image)
print(text)
if mp3 == 1:
try:
create_mp3(text)
except:
trycount += 1
if trycount < 3:
ocr()
else:
print("Some problems with connection maybe")
trycount2 = 0
def create_mp3(text, lang="en"):
s = gTTS(text, lang=lang)
print("Wait a second...")
time.sleep(3)
s.save(f"text.mp3")
os.system("text.mp3")
trycount2 = 0
def clip():
global trycount2
win32clipboard.OpenClipboard()
data = win32clipboard.GetClipboardData()
win32clipboard.CloseClipboard()
try:
create_mp3(data)
except:
trycount2 += 1
if trycount2 < 3:
ocr()
else:
print("Some problems with connection maybe")
trycount2 = 0
click1 = 0
x1 = 0
y1 = 0
def on_click(x, y, button, pressed):
global click1, x1, y1, listener
if pressed:
if click1 == 0:
x1 = x
y1 = y
click1 = 1
else:
grab(x1, y1, x, y)
listener.stop()
sys.exit()
def start():
global listener
root.destroy()
print("Click once on top left and once on bottom right")
# with Listener(on_move=on_move, on_click=on_click, on_scroll=on_scroll) as listener:
with Listener(on_click=on_click) as listener:
listener.join()
root = tk.Tk()
root.title("GRAUTESC 2 - Text to Audio APP")
root.geometry("600x500")
but = tk.Button(root, text="Grab to audio", command=start, width=20, height=3, bg="gold")
but.pack()
butclip = tk.Button(root, text="Audio from clipboard", command=clip, width=20,height=3, bg="gold")
butclip.pack()
counter = 0
def lab_print(event):
ocr(slides[0], mp3=0)
root.mainloop()
 Subscribe to the newsletter for updates
Subscribe to the newsletter for updates Tkinter templates
Tkinter templatesTwitter: @pythonprogrammi - python_pygame
Videos
Speech recognition gamePygame's Platform Game

Other Pygame's posts